Apr 7, 2025
WHY DO PROMPTS FAIL? AND WHY WILL THEY FAIL?
Prompts fail. But why? It seems there are three key factors: cognition, context, and alignment. In this post, I’ll show you that as models become asymptotically smarter and gain increasingly extensive context, the sole persistent reason prompts will continue failing is alignment.
Before diving into core reasons, we must first define a fourth, perpendicular vector to the other forces—scope.
Scope
A single sentence prompt can encapsulate a small or large scope. For example:
- “Write a function that adds two integers” has low scope.
- “Write me a chat app” clearly has high scope.
There is a hidden relationship between prompt length and scope. You can simply think of it as compression:
Compression = scope / length(prompt)
In other words, how much information are you compressing into a given prompt? With every prompt, there’s a lossless part (clear, unambiguous intent) and a lossy part (unstated assumptions, intentions, constraints).
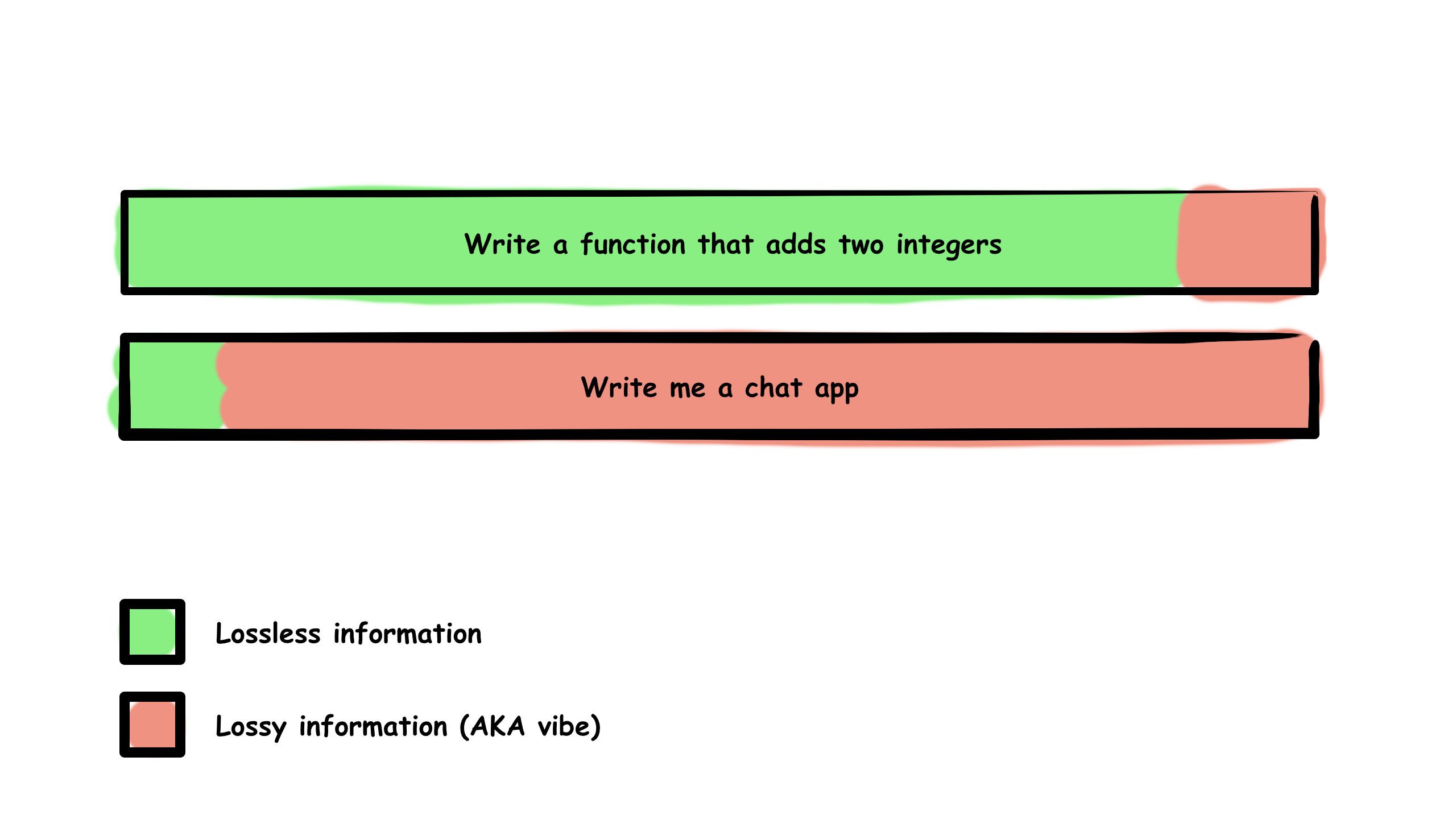
If the scope is large but the prompt is small, you’re effectively asking the model to make up the rest—to generate meaning out of ambiguity.
In low-scope prompts, like adding two numbers, the compression is minimal; the model can operate almost losslessly. But as scope increases, fidelity decreases, and now you’re introducing vibes—implicit expectations the model must infer. That’s where things begin to break.
Cognition
Now that we’ve defined scope, let’s talk about cognition. This metric itself could be broken into multiple spatial dimensions (emergent abilities, reasoning, generalization, etc.), but let’s simplify it here: cognition is essentially how smart the model is.
Over time, as models evolve and scale, we’d expect their cognitive abilities to approach an asymptotic error-free limit (at least with respect to “lossless” well-defined prompts):
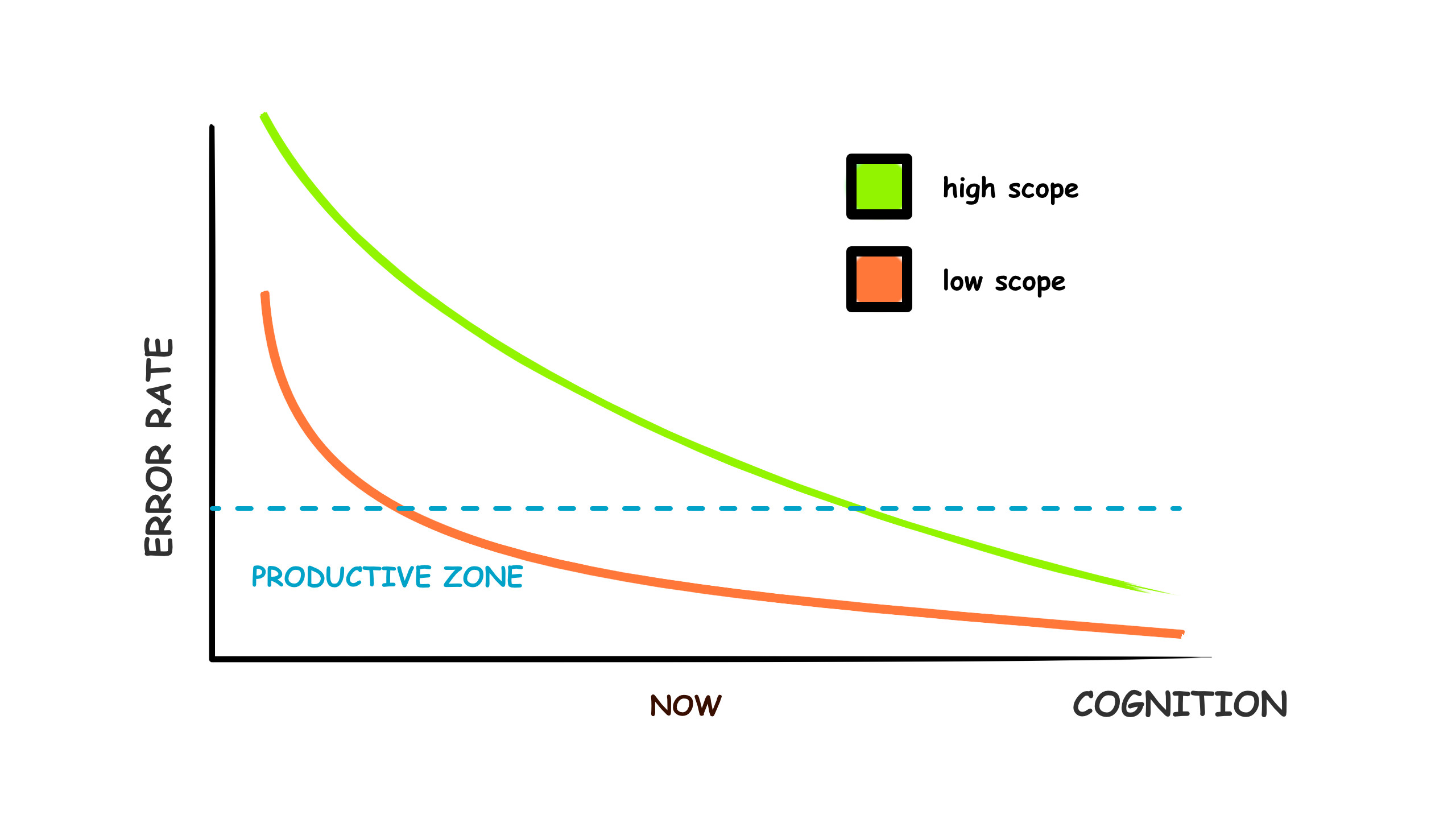
The release of OpenAI’s O1 model marks a moment when well-defined prompts in a local context have become impressively usable. A breakthrough for high-context tasks will most likely follow soon.
Context
Like cognition, context is multidimensional. In programming, context is more than just the immediate prompt or the current code snippet; it includes understanding the entire codebase, why certain decisions were made, historical documentation, user feedback, and even the nuance of client meetings.
Context is still waiting for its ‘O1’ moment, but great strides are being made every day. Recent tools like Augment Code show promising progress—an “Augment Context Engine” that tracks and understands your codebase. Maybe this is our “GPT-3.5 moment” for context: far from perfect, but usable.
Alignment
Unlike cognition and context, alignment is subtler and more elusive. Alignment is the art of getting the model to produce exactly what you expect, even though you haven’t explicitly stated all details.
Think of alignment as how accurately the model captures your implicit intentions. Its improvement trajectory is gentler than those of cognition and context because alignment fundamentally depends on communication.
The model can’t inherently know which protocol you want to use or what color the button should be unless you explicitly tell it.
Currently, human-to-model communication relies primarily on text, which limits our bandwidth significantly. While better graphical interfaces or new communication methods could help, the alignment issue won’t see exponential improvements comparable to cognition and context—at least not until we achieve direct thought-based communication.
This means alignment will soon become the primary bottleneck limiting AI productivity.